2.pandas
joker ... 2022-4-7 大约 3 分钟
# 2.pandas
# 2.1 基本介绍
import pandas as pd
import numpy as np
s=pd.Series([1,3,6,np.nan,44,1])
print(s)
dates=pd.date_range("20210701",periods=6)
print(dates)
df=pd.DataFrame(np.random.randn(6,4),index=dates,columns=["a","b","c","d"])
print(df)
# 可以使用字典的方式进行
df2=pd.DataFrame({"A":1,"B":"kk","C":np.array([1,2,3])})
print(df2)
# 打印每一列的属性
print(df2.dtypes)
# 打印列的值
print(df2.columns)
print(df2.T)
# 进行排序
print(df2.sort_index(axis=1,ascending=False))
print(df2.sort_index(axis=0,ascending=False))
# 对于矩阵中的值进行排序
print(df2.sort_values(by="C",ascending=False))
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
# 2.2 选择数据
import pandas as pd
import numpy as np
dates=pd.date_range("20210703",periods=6)
df=pd.DataFrame(np.arange(24).reshape((6,4)),index=dates,columns={"A","B","C","D"})
print(df["A"])
print(df.A)
print("0-3 行",df[0:3])
print(df["20210703":"20210705"])
# loc 是纯标签的筛选
print(df.loc["20210704"])
print(df.loc["20210704",["A","B"]])
# iloc 是纯数字的筛选
print(df.iloc[3,1])
print(df.iloc[3:5,1:3])
# ix 是混合的筛选
print(df.ix[:3,["A","C"]])
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# 2.3 设置值
import pandas as pd
import numpy as np
dates=pd.date_range("20210703",periods=6)
df=pd.DataFrame(np.arange(24).reshape((6,4)),index=dates,columns={"A","B","C","D"})
# 选择标签,然后设置值
df.iloc[2,2]=1111
print(df)
df.loc["20210703","B"]=2222
print(df)
df.B[df.A>8]=0
print(df)
df["E"]=np.nan
print(df)
df["F"]=[1,2,3,4,5,6]
print(df)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# 2.4 处理丢失数据
import pandas as pd
import numpy as np
dates=pd.date_range("20210703",periods=6)
df=pd.DataFrame(np.arange(24).reshape((6,4)),index=dates,columns={"A","B","C","D"})
df["E"]=np.nan
df.iloc[0,1]=np.nan
df.iloc[1,2]=np.nan
print(df)
# 如果一行中,有nan ,就全部丢掉,这边是全部丢掉
print(df.dropna(axis=0,how="any"))
# 丢掉列,某一列全部是nan,才全部丢掉
print(df.dropna(axis=1,how="all"))
# 填充其中的nan
print(df.fillna(value=0))
print(df.isnull())
# 返回是否有一个nan
print(np.any(df.isnull())==True)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
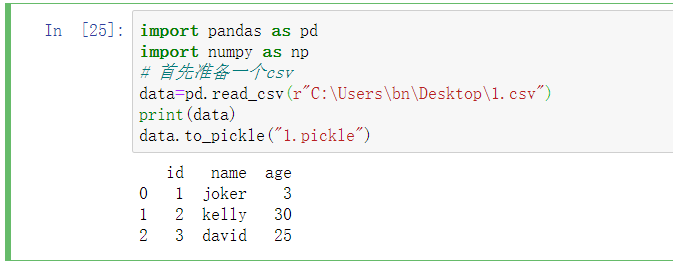
# 2.5 导入导出数据
api 网址
https://pandas.pydata.org/docs/reference/io.html
1
样例
import pandas as pd
import numpy as np
# 首先准备一个csv
data=pd.read_csv(r"C:\Users\bn\Desktop\1.csv")
print(data)
data.to_pickle("1.pickle")
1
2
3
4
5
6
2
3
4
5
6
# 2.6 合并
# concat
import pandas as pd
import numpy as np
df1=pd.DataFrame(np.ones((3,4))*0,columns=["a","b","c","d"])
df2=pd.DataFrame(np.ones((3,4))*1,columns=["a","b","c","d"])
df3=pd.DataFrame(np.ones((3,4))*2,columns=["a","b","c","d"])
print(df1)
print(df2)
res=pd.concat([df1,df2,df3],axis=0)
print(res)
df1=pd.DataFrame(np.ones((3,4))*0,columns=["a","b","c","d"],index=[1,2,3])
df2=pd.DataFrame(np.ones((3,4))*1,columns=["b","c","d","e"],index=[2,3,4])
res=pd.concat([df1,df2])
# 多余的部分会用NaN 连接
print(res)
# 寻找相同的列
res=pd.concat([df1,df2],join="inner",ignore_index=True)
print(res)
# 还有append数据
df1=pd.DataFrame(np.ones((3,4))*0,columns=["a","b","c","d"])
df2=pd.DataFrame(np.ones((3,4))*1,columns=["a","b","c","d"])
df3=pd.DataFrame(np.ones((3,4))*2,columns=["a","b","c","d"])
res=df1.append([df2,df3])
print(res)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
# merge
import pandas as pd
import numpy as np
left=pd.DataFrame({"key":["K0","K1","K2","K3"],
"A":["A0","A1","A2","A3"],
"B":["B0","B1","B2","B3"],
})
right=pd.DataFrame({"key":["K0","K1","K2","K3"],
"C":["C0","C1","C2","C3"],
"D":["D0","D1","D2","D3"],
})
print(left)
print(right)
res=pd.merge(left,right,on="key")
print(res)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
2
3
4
5
6
7
8
9
10
11
12
13
14
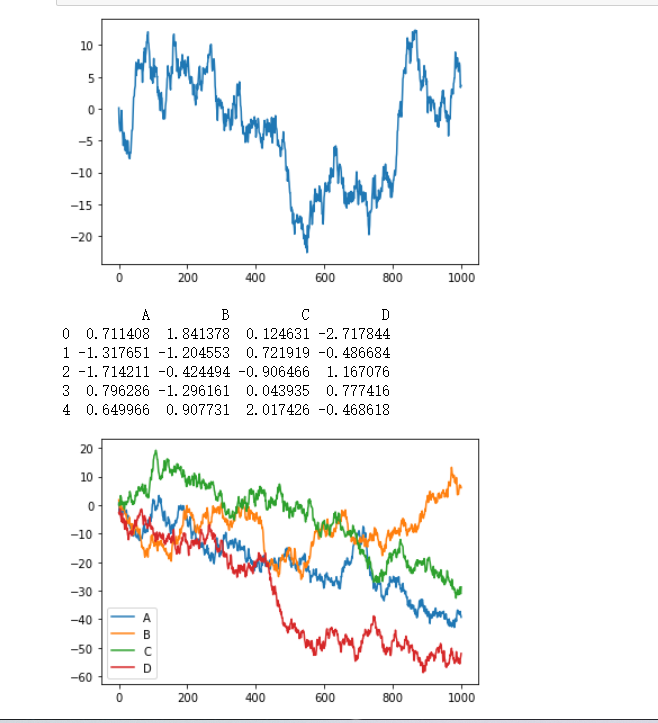
# 2.7 打印
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
data=pd.Series(np.random.randn(1000),index=np.arange(1000))
data=data.cumsum()
data.plot()
plt.show()
# 矩阵的数据
data=pd.DataFrame(np.random.randn(1000,4),
index=np.arange(1000),columns=list("ABCD"))
print(data.head())
data=data.cumsum()
data.plot()
plt.show()
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16