LSTM
joker ... 2022-4-7 大约 7 分钟
# LSTM
# 1.简介
LSTM(Long Short Term Memory ) 长短期记忆神经网络。
在RNN的基础上加入了遗忘机制,选择性的保留或遗忘前期的某些数据,且不再采用乘法而是加法以避免梯度爆炸的问题
# 2.架构讲解
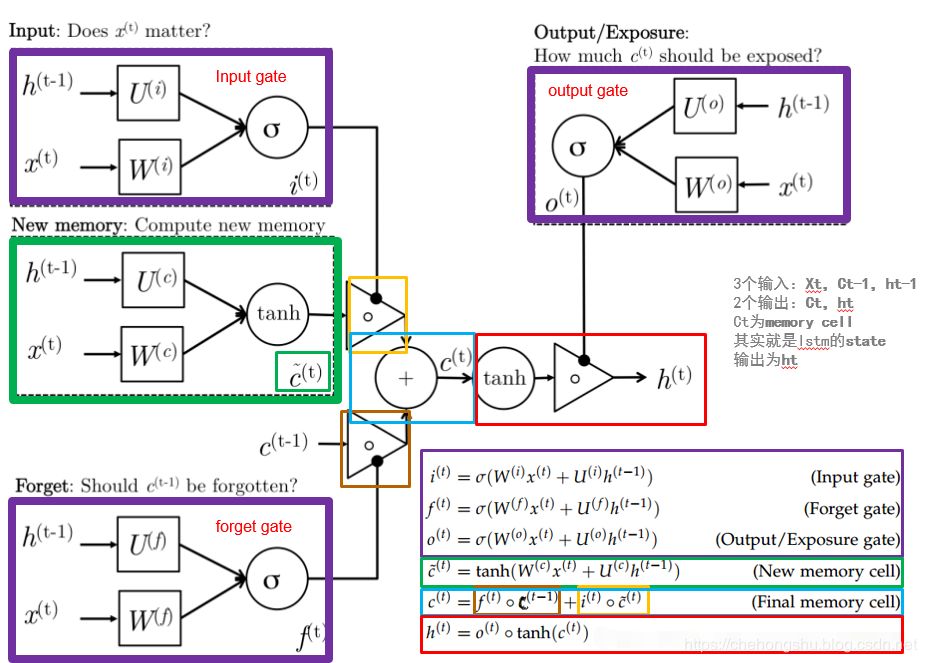
# 2.1 输入门,忘记门和输出门
先简单介绍一下一般的RNN
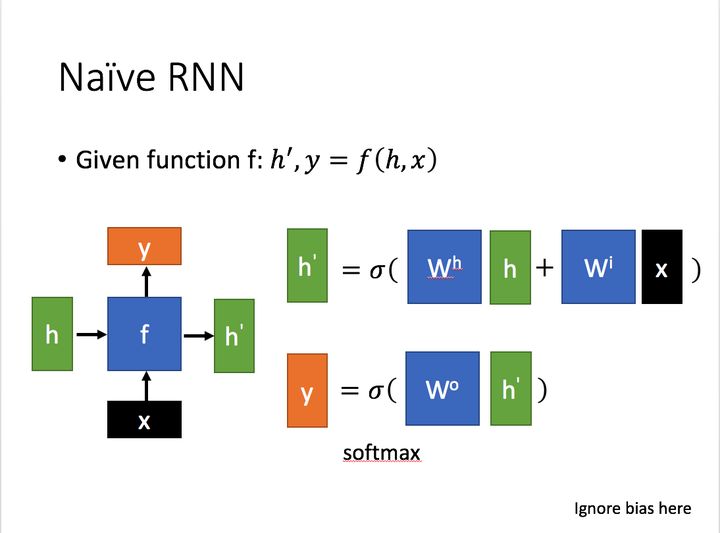
为当前状态下数据的输入,表示接受到的上一个节点的输入
为当前状态下的输出,而为传递到下一个节点的输出
通过上图的公式可以看到与和的值都相关
而则常常使用投入到一个线性层(主要是进行维度映射)然后使用softmax进行分类得到需要的数据。
对这里的如何通过算得到往往看具体模型的使用方式。
通过序列形式的输入,我们能够得到如下形式的RNN。
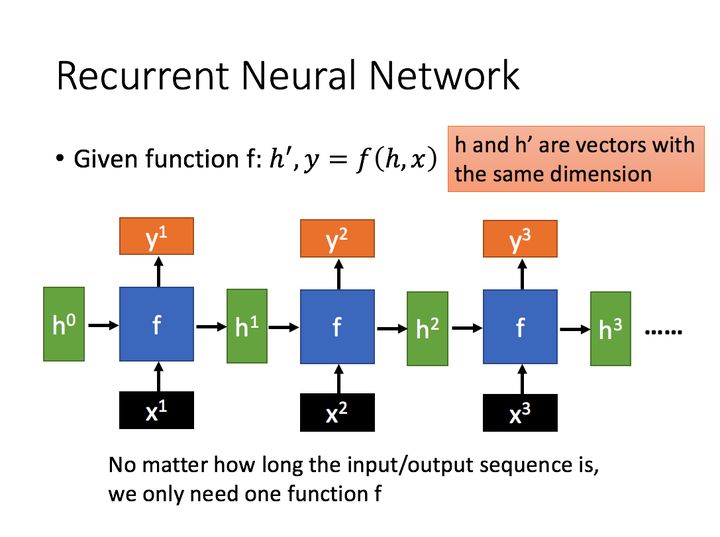
LSTM 同样是这样的结构,但是重复的模块拥有一个不同的结构。不同于 单一神经网络层,这里是有四个,以一种非常特殊的方式进行交互。

我们来细化一下长短期记忆网络的数学表达。
假设有个隐藏单元,批量大小为,输入数为,因此输入为,前一时间步的隐状态为.相应地,时间步的门被定义如下:输出门是,遗忘门是,输出门是.他们的计算方法如下
其中为权重参数,为偏置
# 2.2 计算候选记忆元
由于还没有指定各种门的操作,所以先介绍候选记忆元,,他的计算与上面描述的三个门的计算类似,但是使用函数作为激活函数,函数的值范围为下面导出在时间步处的方程
其中和是权重参数,是偏置参数

# 2.3 隐状态
最后,我们需要定义如何计算隐状态,这就是输出门发挥作用的地方。 在长短期记忆网络中,它仅仅是记忆元的的门控版本。这就确保了的值始终在区间内:
只有输出门接近1,我们就能够有效地将所有记忆信息传递给预测部分,而对于输出门接近0,我们只保留记忆元内的 所有信息,而不需要更新隐状态。

LSTM内部主要有三个阶段:
忘记阶段。这个阶段主要是对上一个节点传进来的输入进行选择性忘记。简单来说就是会 “忘记不重要的,记住重要的”。
具体来说是通过计算得到的,来作为忘记门控,来控制上一个状态的哪些需要留哪些需要忘。
选择记忆阶段。这个阶段将这个阶段的输入有选择性地进行“记忆”。主要是会对输入,进行选择记忆。哪些重要则着重记录下来,哪些不重要,则少记一些。当前的输入内容由前面计算得的表示。而选择的门控信号则是由来进行控制。
将上面两步得到的结果相加,即可得到传输给下一个状态的
输出阶段。这个阶段将决定哪些将会被当成当前状态的输出。主要是通过来进行控制。并且还对上一阶段得到的
①来了新东西后,根据新东西决定一下旧的东西要不要忘掉; ②新的东西有多少要记住; ③记住的东西有多少要拿出来说。
# 3.代码
# 初始化参数
def get_lstm_params(vocab_size, num_hiddens, device):
num_inputs = num_outputs = vocab_size
def normal(shape):
return torch.randn(size=shape, device=device)*0.01
def three():
return (normal((num_inputs, num_hiddens)),
normal((num_hiddens, num_hiddens)),
torch.zeros(num_hiddens, device=device))
W_xi, W_hi, b_i = three() # 输入门参数
W_xf, W_hf, b_f = three() # 遗忘门参数
W_xo, W_ho, b_o = three() # 输出门参数
W_xc, W_hc, b_c = three() # 候选记忆元参数
# 输出层参数
W_hq = normal((num_hiddens, num_outputs))
b_q = torch.zeros(num_outputs, device=device)
# 附加梯度
params = [W_xi, W_hi, b_i, W_xf, W_hf, b_f, W_xo, W_ho, b_o, W_xc, W_hc,
b_c, W_hq, b_q]
for param in params:
param.requires_grad_(True)
return params
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
# 定义模型
在初始化函数中, 长短期记忆网络的隐状态需要返回一个额外的记忆元, 单元的值为0,形状为(批量大小,隐藏单元数)。 因此,我们得到以下的状态初始化。
def init_lstm_state(batch_size, num_hiddens, device):
return (torch.zeros((batch_size, num_hiddens), device=device),
torch.zeros((batch_size, num_hiddens), device=device))
1
2
3
2
3
获取输出
def lstm(inputs, state, params):
[W_xi, W_hi, b_i, W_xf, W_hf, b_f, W_xo, W_ho, b_o, W_xc, W_hc, b_c,
W_hq, b_q] = params
(H, C) = state
outputs = []
for X in inputs:
I = torch.sigmoid((X @ W_xi) + (H @ W_hi) + b_i)
F = torch.sigmoid((X @ W_xf) + (H @ W_hf) + b_f)
O = torch.sigmoid((X @ W_xo) + (H @ W_ho) + b_o)
C_tilda = torch.tanh((X @ W_xc) + (H @ W_hc) + b_c)
C = F * C + I * C_tilda
H = O * torch.tanh(C)
Y = (H @ W_hq) + b_q
outputs.append(Y)
return torch.cat(outputs, dim=0), (H, C)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# 4. 小结
两条主线:
线:记忆线 线:输出线
一个核心门:
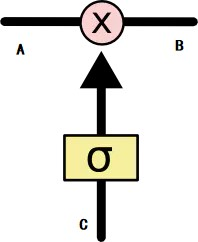
σ为决定门(sigmoid)。根据C的情况,决定A中保留多少,对A进行筛选后输出为B。
GRU在这里对LSTM进行了优化,所以LSTM比较复杂
换个图讲解一下
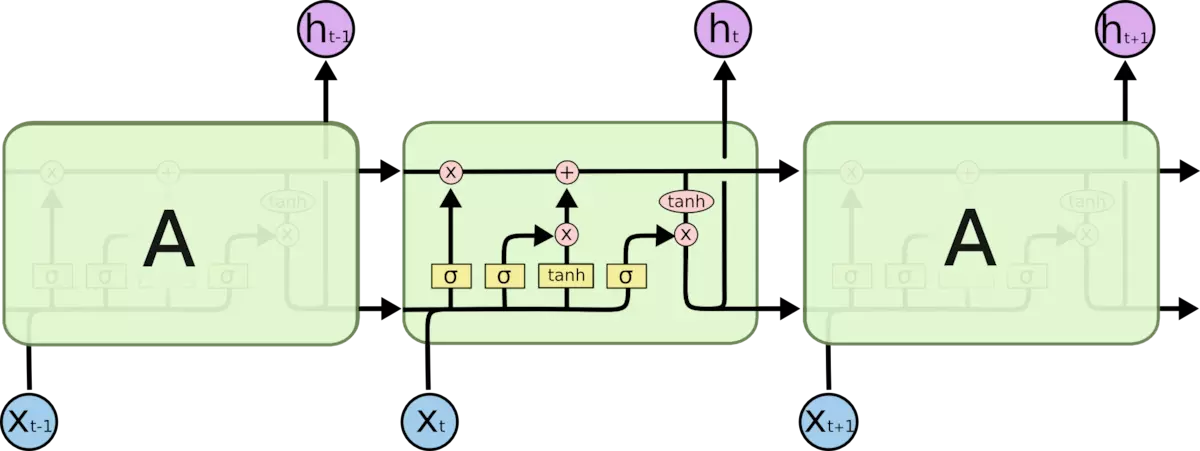
**①一个神经元的两个输入数据为:**前一个神经元的输出和新的输入。
②遗忘
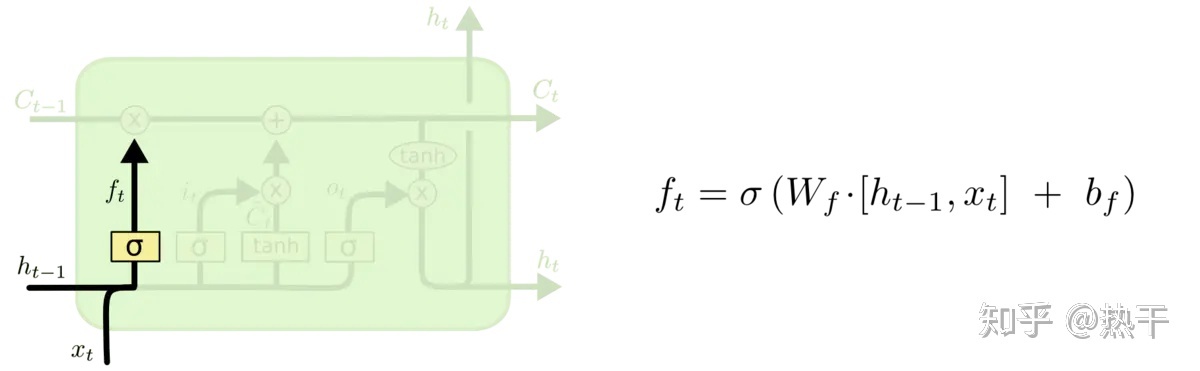
来了新东西后,根据新东西决定一下旧的东西要不要忘掉。
两个输入数据,经过决定门,得到一个0~1之间的数,乘到原始记忆库中,将中的部分保留,其余的遗忘。即原始记忆库中只有这一部分保留,其余的遗忘;而是由两个输入数据决定的。
③输入
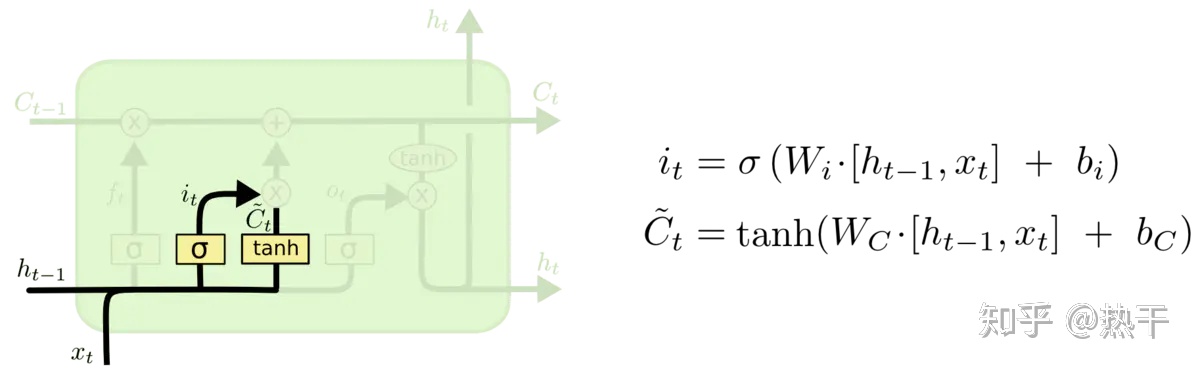
新的东西有多少要记住。
两个输入数据,经过tanh门之后得到一个候选输入;而候选输入中不是所有东西都要加入到记忆库中,因此利用两个输入数据,经过决定门得到it,即候选输入中需要保留的比重。将被筛选后的候选输入加入到原始记忆库中。
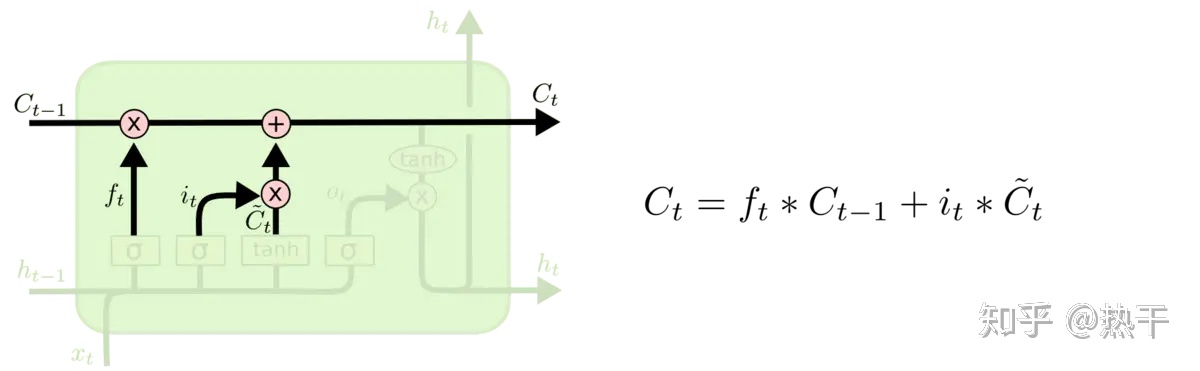
此时记忆库,从经过:一次选择性遗忘的相乘,和一次选择性记忆的相加,成为了新的记忆库。
④输出
- 长短期记忆网络有三种类型的门:输入门、遗忘门和输出门。
- 长短期记忆网络的隐藏层输出包括“隐状态”和“记忆元”。只有隐状态会传递到输出层,而记忆元完全属于内部信息。
- 长短期记忆网络可以缓解梯度消失和梯度爆炸。
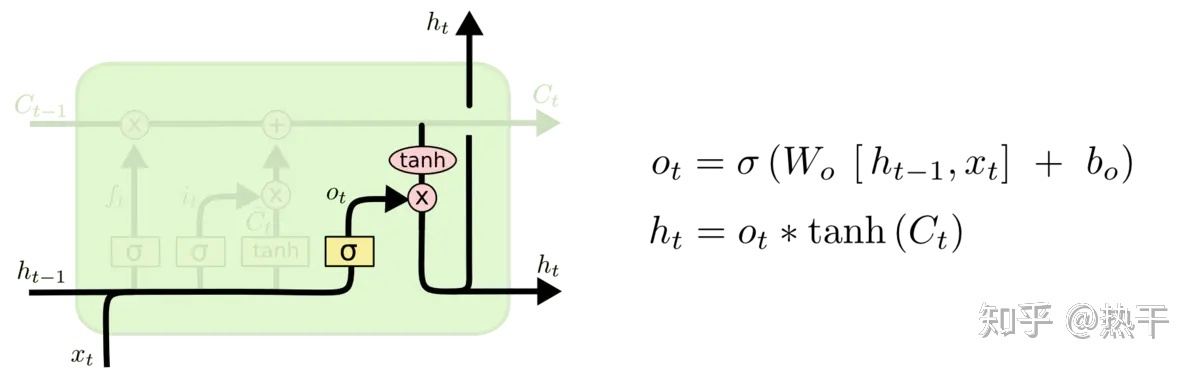
记住的东西有多少要拿出来说。
新的记忆库Ct已经成型,经过tanh门后,再经由决定门Ot决定哪些要作为输出。决定门Ot也是从两个输入值计算而来。
# 缺点
一个神经元中存在3个门,相当于每个神经元都是原来RNN计算量的3倍以上,十分浪费算力。
无法对不等长序列数据进行处理。
# 5. 和GRU区别
GRU将遗忘门和输入门合并成更新门,同时将记忆单元与隐藏层合并成了重置门,进而让整个结构运算变得更加简化且性能得以增强。
LSTM的参数量是GRU的参数量的倍