4.3 上采样方法介绍
joker ... 2022-4-7 大约 21 分钟
# 4.3 上采样方法介绍
在图像分割中,因为FCN的提出,上采样操作成为了分割中不可或缺的部分。上采样就是将提取到的feature map还原到原始分辨率大小的操作,但是这里要注意的是上采样不是下采样的逆过程,也就是说上采样输出的图像和下采样之前的图像是不一样的。
上采样操作主要分为几种方法:
转置卷积
feature maps补0,然后做卷积操作
线性差值
插值法不需要学习任何的参数,只是根据已知的像素点对未知的点进行预测估计,从而可以扩大图像的尺寸,达到上采样的效果
反池化unpooling
在空隙中填充 0
unsampling
在空隙中填充同样的值
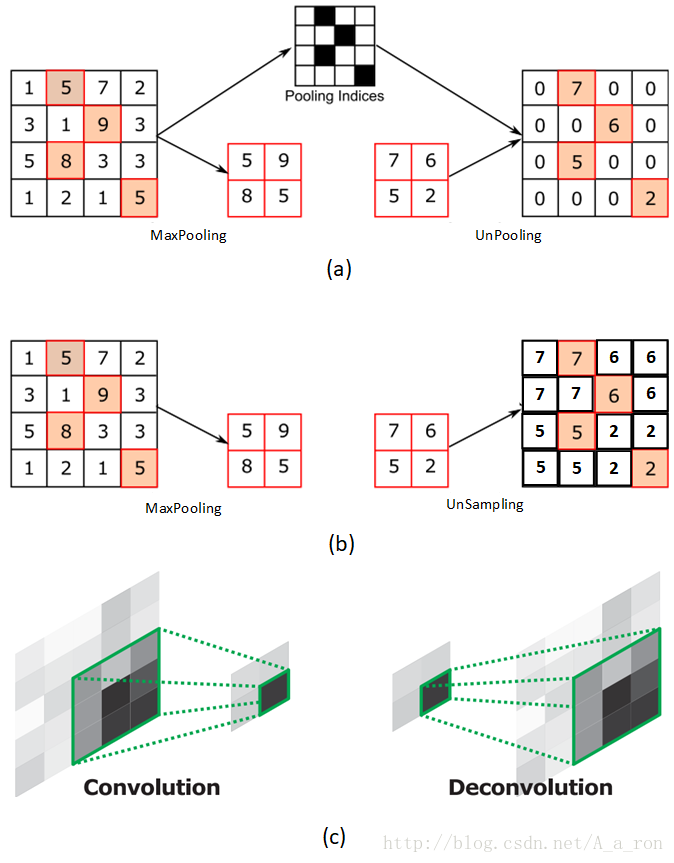
图(a)表示UnPooling的过程,特点是在Maxpooling的时候保留最大值的位置信息,之后在unPooling阶段使用该信息扩充Feature Map,除最大值位置以外,其余补0。
与之相对的是图(b),两者的区别在于UnSampling阶段没有使用MaxPooling时的位置信息,而是直接将内容复制来扩充Feature Map。从图中即可看到两者结果的不同。
图(c)为反卷积的过程,反卷积是卷积的逆过程,又称作转置卷积。最大的区别在于反卷积过程是有参数要进行学习的(类似卷积过程),理论是反卷积可以实现UnPooling和unSampling,只要卷积核的参数设置的合理。
# 1. 转置卷积
一句话介绍 对feature maps补0,然后做卷积操作
# 1.1 简介
o=自己所想要的输出
i=输入
p=填充
s=补偿
第一种关系
==如果你想要的输出o满足一下的情况==
此时反卷积的输入和输出尺寸为
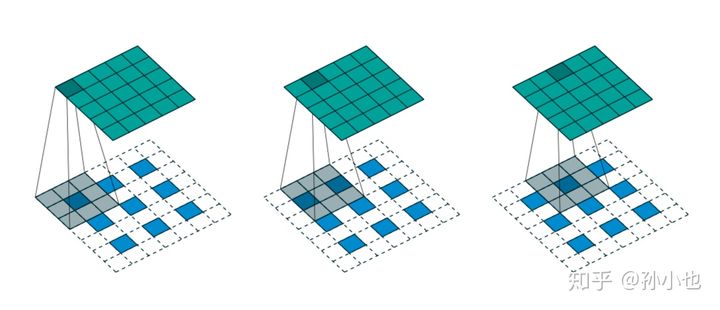
如上图所示,我们选择一个输入的尺寸为,卷积核的尺寸为.
步长为。填充。
输出
第二种情况
==如果你想要的输出o不满足一下的情况==
此时反卷积的输入输出尺寸关系为:
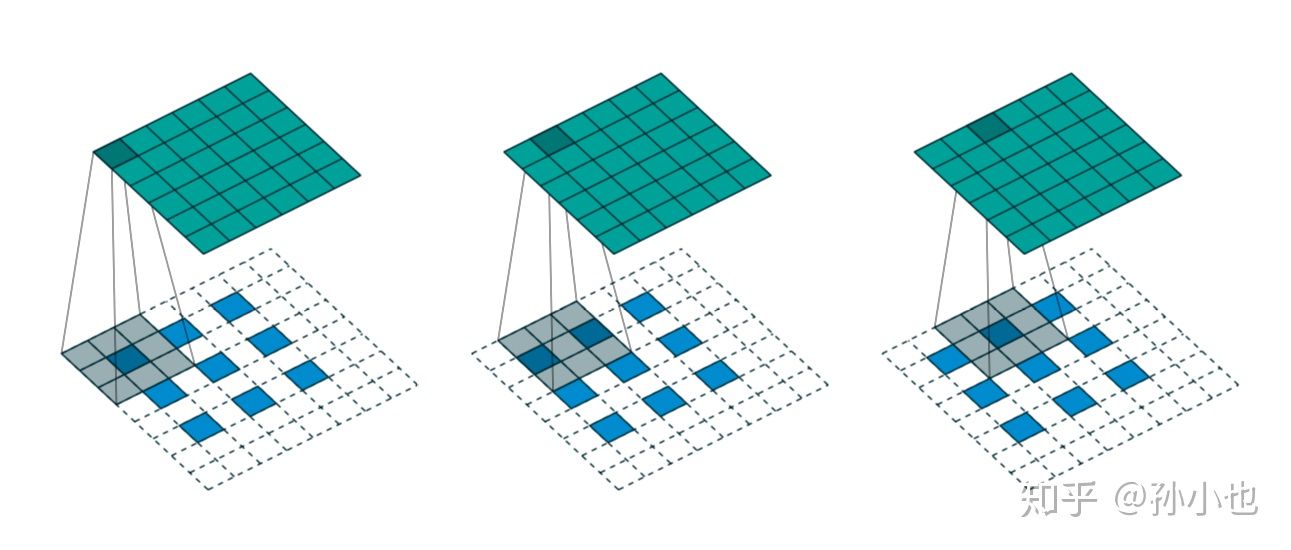
如上图所示,我们想要的输出为6.
我们选择一个输入的尺寸为,卷积核的尺寸为.
步长为。填充。
即输出尺寸为
# 1.2 nn.ConvTranspose2d
nn.ConvTranspose2d(in_channels,
out_channels,
kernel_size,
stride=1,
padding=0,
output_padding=0,
groups=1,
bias=True,
dilation=1)
1
2
3
4
5
6
7
8
9
2
3
4
5
6
7
8
9
参数详解
padding(int or tuple, optional) - 输入的每一条边补充0的层数,高宽都增加2*paddingoutput_padding(int or tuple, optional) - 输出边补充0的层数,高宽都增加paddingstrides:步长。每次窗口滑动距离
样例
import torch
import torch.nn as nn
in_channels = 1
out_channels = 1
input_image = torch.randn(1, in_channels, 4, 4)
# bach_size=1, channel=1 ,width=4,height=4
print(input_image)
model = nn.ConvTranspose2d(in_channels, out_channels, kernel_size=(1, 1), stride=(1, 1))
# s(i-1)-2p+k =1*(4-1)-2*0+1=4
out = model(input_image)
print(out.shape)
print(out)
model_2 = nn.ConvTranspose2d(in_channels, out_channels, kernel_size=(2, 2), stride=(2, 2), padding=(1, 1))
# s(i-1)-2p+k =2*(4-1)-2*1+2=6
out_2 = model_2(input_image)
print(out_2.shape)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
输出
tensor([[[[ 0.5473, 0.3649, 1.8538, -0.9376],
[ 0.4194, 1.3776, -0.0543, -0.9235],
[-1.8235, 0.0083, -0.4024, 1.3257],
[-0.2997, -1.2016, -0.7124, 1.1128]]]])
torch.Size([1, 1, 4, 4])
tensor([[[[ 0.3332, 0.4445, -0.4643, 1.2395],
[ 0.4112, -0.1736, 0.7003, 1.2308],
[ 1.7801, 0.6621, 0.9128, -0.1419],
[ 0.8501, 1.4006, 1.1020, -0.0120]]]],
grad_fn=<SlowConvTranspose2DBackward0>)
torch.Size([1, 1, 6, 6])
1
2
3
4
5
6
7
8
9
10
11
2
3
4
5
6
7
8
9
10
11
# 1.3 应用
# 1.3.1 反卷积在FCN中的应用
在图像语义分割网络 FCN-32s 中,上采样反卷积操作的输入每张的尺寸是.
我们希望进行一次上采样后能恢复成原始图像的尺寸,代入公式
根据上述公式,我们可以得到一个关于三者之间的关系的等式
通过实验,最终找出了最合适的一组数据:
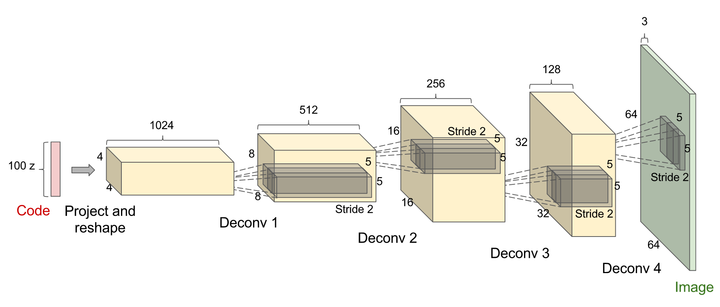
# 1.3.2 GAN中的应用
GAN对抗式生成网络中,由于需要从输入图像到生成图像,自然需要将提取的特征图还原到和原图同样尺寸的大小,即也需要反卷积操作。
转置卷积的一个很有趣的应用是GAN(Generative Adversarial Network)里用来生成图片
# 1.3.3 CNN可视化
CNN可视化,通过反卷积将卷积得到的feature map还原到像素空间,来观察feature map对哪些pattern相应最大,即可视化哪些特征是卷积操作提取出来的;
# 1.4 叫转置卷积的原因
假设输入图像尺寸为,元素矩阵为
卷积核尺寸为,元素矩阵为
步长,填充
输出图像大小
用矩阵乘法描述卷积
把的元素矩阵展开称一个列向量
将输出图像的元素矩阵展开称一个列向量
对于输入的元素矩阵和输出的元素矩阵,用矩阵运算描述这个过程
通过推导,我们可以得到稀疏矩阵

反卷积的操作就是要对这个矩阵运算过程进行逆运算,即通过和得到.根据各个矩阵的尺寸大小。我们能很轻易的得到计算的过程,即为反卷积的操作
但是,如果你代入数字计算会发现,反卷积的操作只是恢复了矩阵的尺寸大小并不能婚服的每个元素值
==这个就是为啥叫做转置卷积==
参考链接
反卷积(Transposed Convolution)详细推导 - 知乎 (zhihu.com) (opens new window)
参考链接https://blog.csdn.net/e01528/article/details/84667302
# 2. 线性差值
插值法不需要学习任何的参数,只是根据已知的像素点对未知的点进行预测估计,从而可以扩大图像的尺寸,达到上采样的效果。
差值就是利用已知点来估计未知点的值。一维上,可以用两点求出斜率,再根据位置关系来求插入点的值。
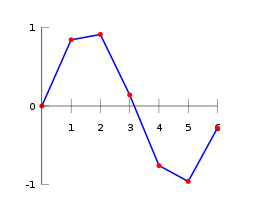
插值(interpolation)在数学上指的是 一种估计方法,其根据已知的离散数据点去构造新的数据点。以曲线插值为例子,如Fig 1.1所示的曲线线性插值为例,其中==红色数据点是已知的数据点==,而==蓝色线是根据相邻的两个红色数据点进行线性插值估计出来==的。
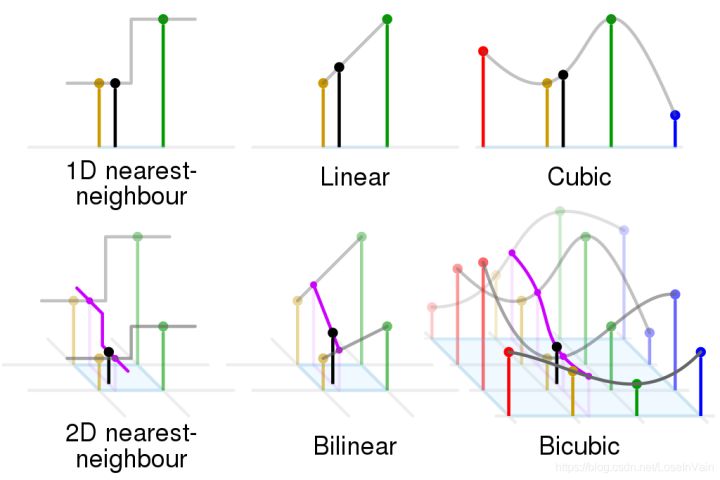
一维的曲线插值的原理可以推广到任意维度的数据形式上,比如我们常见的图像是一种二维数据,就可以进行二维插值,常见的插值方法如Fig 1.2所示。
# 2.1 公式
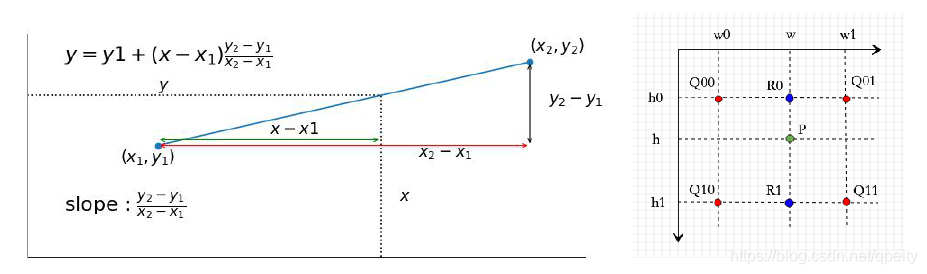
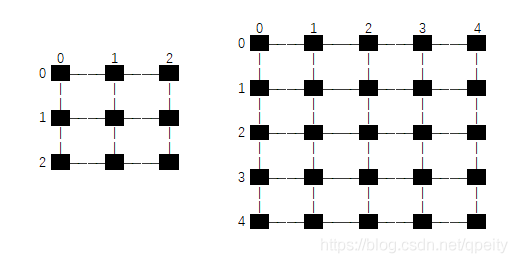
在二维平面上也可以用类似的办法来估计插入点的值。如图,已知四点,四点的值与坐标值和的点的值。思路是
- 先用方向一维的线性差值,根据求出点,根据求出点
- 再用方向一维线性差值,根据和求出点
就有如下公式
具体到图像的双线性差值问题,我们可以理解成将图片进行了放大,但不使图像变成大块的斑点状,而是增大了图像的分辨率,多出来的像素就是双线性差值的结果。图像周边4点一定是临近的,也就是说
上面的公式简化为
# 2.2 坐标变换
对于第一个问题,目标图像的坐标映射搭配原图像上求出,有两种思路
第一种是把像素点看成是1×1大小的方块,像素点位于方块的中心,坐标转换时,HW方向的坐标都要加0.5才能对应起来。pytorch里面叫做torch.nn.functional.interpolate(align_corners=False)。
举例,如图原图像是一个的图像,放大到,每个像素点都是位于方形内的黑色小点。设是原图像的大小,本例是,是目标图像的大小,本例是5×5。换算公式为
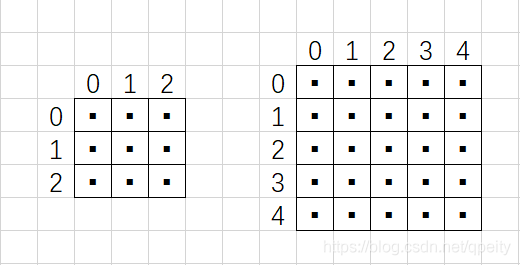
第二种是上下左右相邻的像素点之间连线,像素点都位于交点上,坐标转换时,HW方向的总长度都要减少1才能对应起来g。pytorch里面叫做torch.nn.functional.interpolate(align_corners=True)。
举例,一个3×3的图像放大到5×5,每个像素点都是位于交点的黑色小点。设是原图像大小,本例是是目标图像的大小,本例是5×5。换算时,我们取边的长度,也就是HW方向各减1,也就是从2×2变成4×4。这样就有个结论就是变换以后目标图像四个顶点的像素值一定和原图像四个顶点像素值一样。换算公式为
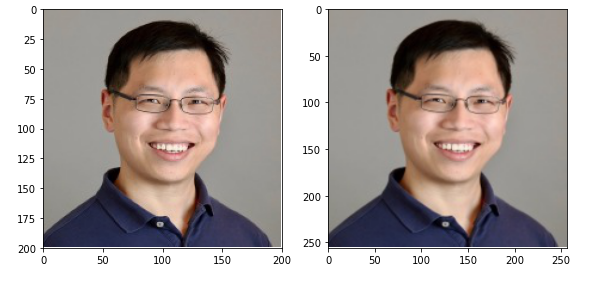
# 2.3 用numpy矩阵实现
是对一张图像的,维度HWC;采用numpy矩阵实现,速度快;
import matplotlib.pyplot as plt
import matplotlib.image as mpimg
from PIL import Image
import numpy as np
import os
import torch
import torch.nn.functional as F
def bilinear_interpolation(src, dst_size, align_corners=False):
"""
双线性插值高效实现
:param src: 源图像H*W*C
:param dst_size: 目标图像大小H*W
:return: 双线性插值后的图像
"""
(src_h, src_w, src_c) = src.shape # 原图像大小 H*W*C
(dst_h, dst_w), dst_c = dst_size, src_c # 目标图像大小H*W*C
if src_h == dst_h and src_w == dst_w: # 如果大小不变,直接返回copy
return src.copy()
# 矩阵方式实现
h_d = np.arange(dst_h) # 目标图像H方向坐标
w_d = np.arange(dst_w) # 目标图像W方向坐标
if align_corners:
h = float(src_h - 1) / (dst_h - 1) * h_d
w = float(src_w - 1) / (dst_w - 1) * w_d
else:
h = float(src_h) / dst_h * (h_d + 0.5) - 0.5 # 将目标图像H坐标映射到源图像上
w = float(src_w) / dst_w * (w_d + 0.5) - 0.5 # 将目标图像W坐标映射到源图像上
h = np.clip(h, 0, src_h - 1) # 防止越界,最上一行映射后是负数,置为0
w = np.clip(w, 0, src_w - 1) # 防止越界,最左一行映射后是负数,置为0
h = np.repeat(h.reshape(dst_h, 1), dst_w, axis=1) # 同一行映射的h值都相等
w = np.repeat(w.reshape(dst_w, 1), dst_h, axis=1).T # 同一列映射的w值都相等
h0 = np.floor(h).astype(int) # 同一行的h0值都相等
w0 = np.floor(w).astype(int) # 同一列的w0值都相等
h0 = np.clip(h0, 0, src_h - 2) # 最下一行上不大于src_h - 2,相当于padding
w0 = np.clip(w0, 0, src_w - 2) # 最右一列左不大于src_w - 2,相当于padding
h1 = np.clip(h0 + 1, 0, src_h - 1) # 同一行的h1值都相等,防止越界
w1 = np.clip(w0 + 1, 0, src_w - 1) # 同一列的w1值都相等,防止越界
q00 = src[h0, w0] # 取每一个像素对应的q00
q01 = src[h0, w1] # 取每一个像素对应的q01
q10 = src[h1, w0] # 取每一个像素对应的q10
q11 = src[h1, w1] # 取每一个像素对应的q11
h = np.repeat(h[..., np.newaxis], dst_c, axis=2) # 图像有通道C,所有的计算都增加通道C
w = np.repeat(w[..., np.newaxis], dst_c, axis=2)
h0 = np.repeat(h0[..., np.newaxis], dst_c, axis=2)
w0 = np.repeat(w0[..., np.newaxis], dst_c, axis=2)
h1 = np.repeat(h1[..., np.newaxis], dst_c, axis=2)
w1 = np.repeat(w1[..., np.newaxis], dst_c, axis=2)
r0 = (w1 - w) * q00 + (w - w0) * q01 # 双线性插值的r0
r1 = (w1 - w) * q10 + (w - w0) * q11 # 双线性差值的r1
q = (h1 - h) * r0 + (h - h0) * r1 # 双线性差值的q
dst = q.astype(src.dtype) # 图像的数据类型
return dst
if __name__ == "__main__":
def unit_test2():
image_file = os.path.join(os.getcwd(), 'test.jpg')
image = mpimg.imread(image_file)
print("原图像大小",image.shape)
image_scale = bilinear_interpolation(image, (256, 256))
print("差值后的图像",image_scale.shape)
fig, axes = plt.subplots(1, 2, figsize=(8, 10))
axes = axes.flatten()
axes[0].imshow(image)
axes[1].imshow(image_scale)
axes[0].axis([0, image.shape[1], image.shape[0], 0])
axes[1].axis([0, image_scale.shape[1], image_scale.shape[0], 0])
fig.tight_layout()
plt.show()
pass
unit_test2()
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
结果
原图像大小 (200, 200, 3)
差值后的图像 (256, 256, 3)
1
2
2
# 2.4 用torch张量实现
是对tensor的,维度NCHW;和第二段一样,但是采用了张量,可以批量处理。
import torch
import torch.nn.functional as F
import os
import matplotlib.pyplot as plt
import matplotlib.image as mpimg
def bilinear_interpolate(src, dst_size, align_corners=False):
"""
双线性差值
:param src: 原图像张量 NCHW
:param dst_size: 目标图像spatial大小(H,W)
:param align_corners: 换算坐标的不同方式
:return: 目标图像张量NCHW
"""
src_n, src_c, src_h, src_w = src.shape
dst_n, dst_c, (dst_h, dst_w) = src_n, src_c, dst_size
if src_h == dst_h and src_w == dst_w:
return src.copy()
"""将dst的H和W坐标映射到src的H和W坐标"""
hd = torch.arange(0, dst_h)
wd = torch.arange(0, dst_w)
if align_corners:
h = float(src_h - 1) / (dst_h - 1) * hd
w = float(src_w - 1) / (dst_w - 1) * wd
else:
h = float(src_h) / dst_h * (hd + 0.5) - 0.5
w = float(src_w) / dst_w * (wd + 0.5) - 0.5
h = torch.clamp(h, 0, src_h - 1) # 防止越界,0相当于上边界padding
w = torch.clamp(w, 0, src_w - 1) # 防止越界,0相当于左边界padding
h = h.view(dst_h, 1) # 1维dst_h个,变2维dst_h*1个
w = w.view(1, dst_w) # 1维dst_w个,变2维1*dst_w个
h = h.repeat(1, dst_w) # H方向重复1次,W方向重复dst_w次
w = w.repeat(dst_h, 1) # H方向重复dsth次,W方向重复1次
"""求出四点坐标"""
h0 = torch.clamp(torch.floor(h), 0, src_h - 2) # -2相当于下边界padding
w0 = torch.clamp(torch.floor(w), 0, src_w - 2) # -2相当于右边界padding
h0 = h0.long() # torch坐标必须是long
w0 = w0.long() # torch坐标必须是long
h1 = h0 + 1
w1 = w0 + 1
"""求出四点值"""
q00 = src[..., h0, w0]
q01 = src[..., h0, w1]
q10 = src[..., h1, w0]
q11 = src[..., h1, w1]
"""公式计算"""
r0 = (w1 - w) * q00 + (w - w0) * q01 # 双线性插值的r0
r1 = (w1 - w) * q10 + (w - w0) * q11 # 双线性差值的r1
dst = (h1 - h) * r0 + (h - h0) * r1 # 双线性差值的q
return dst
if __name__ == '__main__':
def unit_test4():
# src = torch.randint(0, 100, (1, 3, 3, 3))
src = torch.arange(1, 1 + 27).view((1, 3, 3, 3))\
.type(torch.float32)
print(src)
dst = bilinear_interpolate(
src,
dst_size=(4, 4),
align_corners=True
)
print(dst)
pt_dst = F.interpolate(
src.float(),
size=(4, 4),
mode='bilinear',
align_corners=True
)
print(pt_dst)
if torch.equal(dst, pt_dst):
print('success')
image_file = os.path.join(os.getcwd(), 'test.jpg')
image = mpimg.imread(image_file)
image_in = torch.from_numpy(image.transpose(2, 0, 1))
image_in = torch.unsqueeze(image_in, 0)
image_out = bilinear_interpolate(image_in, (256, 256))
image_out = torch.squeeze(image_out, 0).numpy().astype(int)
image_out = image_out.transpose(1, 2, 0)
fig, axes = plt.subplots(1, 2, figsize=(8, 10))
axes = axes.flatten()
axes[0].imshow(image)
axes[1].imshow(image_out)
axes[0].axis([0, image.shape[1], image.shape[0], 0])
axes[1].axis([0, image_out.shape[1], image_out.shape[0], 0])
fig.tight_layout()
plt.show()
unit_test4()
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
# 2.5 F.interpolate()
# 参数讲解
x = nn.functional.interpolate(x, scale_factor=8, mode='bilinear', align_corners=False)
1
功能:利用插值方法,对输入的张量数组进行上,下采样操作,换句话说就是科学合理地改变数组的尺寸大小,尽量保持数据完整。
参数解释
input(Tensor):需要进行采样处理的数组。size(int或序列):输出空间的大小scale_factor(float或序列):空间大小的乘数mode(str):用于采样的算法。'nearest'|'linear'|'bilinear'|'bicubic'|'trilinear'|'area'。默认:'nearest'align_corners(bool):在几何上,我们将输入和输出的像素视为正方形而不是点。如果设置为True,则输入和输出张量按其角像素的中心点对齐,保留角像素处的值。如果设置为False,则输入和输出张量通过其角像素的角点对齐,并且插值使用边缘值填充用于边界外值,使此操作在保持不变时独立于输入大小scale_factor。recompute_scale_facto(bool):重新计算用于插值计算的 scale_factor。当scale_factor作为参数传递时,它用于计算output_size。如果recompute_scale_factor的False或没有指定,传入的scale_factor将在插值计算中使用。否则,将根据用于插值计算的输出和输入大小计算新的scale_factor(即,如果计算的output_size显式传入,则计算将相同 )。注意当scale_factor是浮点数,由于舍入和精度问题,重新计算的 scale_factor 可能与传入的不同。
注意点
- 输入的张量数组里面的数据类型必须是
float。 - 输入的数组维数只能是3、4或5,分别对应于时间、空间、体积采样。
- 不对输入数组的前两个维度(批次和通道)采样,从第三个维度往后开始采样处理。
- 输入的维度形式为:批量(batch_size)×通道(channel)×[可选深度]×[可选高度]×宽度(前两个维度具有特殊的含义,不进行采样处理)
size与scale_factor两个参数只能定义一个,即两种采样模式只能用一个。要么让数组放大成特定大小、要么给定特定系数,来等比放大数组。- 如果size或者scale_factor输入序列,则必须匹配输入的大小。如果输入四维,则它们的序列长度必须是2,如果输入是五维,则它们的序列长度必须是3。
- 如果
size输入整数x,则相当于把3、4维度放大成(x,x)大小(输入以四维为例,下面同理)。 - 如果
scale_factor输入整数x,则相当于把3、4维度都等比放大x倍。 mode是’linear’时输入必须是3维的;是’bicubic’时输入必须是4维的;是’trilinear’时输入必须是5维的- 如果
align_corners被赋值,则mode必须是'linear','bilinear','bicubic'或'trilinear'中的一个。 插值方法不同,结果就不一样,需要结合具体任务,选择合适的插值方法。
# 代码用例
import torch.nn.functional as F
import torch
a=torch.arange(12,dtype=torch.float32).reshape(1,2,2,3)
b=F.interpolate(a,size=(4,4),mode='bilinear')
# 这里的(4,4)指的是将后两个维度放缩成4*4的大小
print(a)
print(b)
print('原数组尺寸:',a.shape)
print('size采样尺寸:',b.shape)
1
2
3
4
5
6
7
8
9
10
11
2
3
4
5
6
7
8
9
10
11
输出结果,一二维度大小不会发生变化
# 原数组
tensor([[[[ 0., 1., 2.],
[ 3., 4., 5.]],
[[ 6., 7., 8.],
[ 9., 10., 11.]]]])
# 采样后的数组
tensor([[[[ 0.0000, 0.6250, 1.3750, 2.0000],
[ 0.7500, 1.3750, 2.1250, 2.7500],
[ 2.2500, 2.8750, 3.6250, 4.2500],
[ 3.0000, 3.6250, 4.3750, 5.0000]],
[[ 6.0000, 6.6250, 7.3750, 8.0000],
[ 6.7500, 7.3750, 8.1250, 8.7500],
[ 8.2500, 8.8750, 9.6250, 10.2500],
[ 9.0000, 9.6250, 10.3750, 11.0000]]]])
原数组尺寸: torch.Size([1, 2, 2, 3])
size采样尺寸: torch.Size([1, 2, 4, 4])
# 规定三四维度放缩成4*4大小
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
# 图片用例
from PIL import Image
from matplotlib import pyplot as plt
import numpy as np
import torch.nn as nn
import torch.nn.functional as F
import torch
img = Image.open('./test.jpg')
img = np.array(img)
print("图片的尺寸", img.shape)
plt.imshow(img)
img = np.array(img).transpose(2, 0, 1).reshape(1, 3, 200, 200)
torch_img = torch.FloatTensor(img)
out = F.interpolate(torch_img, size=(300, 300), mode='bilinear')
# 这里的(4,4)指的是将后两个维度放缩成4*4的大小
print(out.shape)
plt.figure()
mean_pool_img = out[0].numpy().transpose((1, 2, 0))
# 把图像变成
mean_pool_img = mean_pool_img.clip(0, 255).astype(int)
plt.imshow(mean_pool_img)
print("上采样后图片大小", mean_pool_img.shape)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
结果如下
图片的尺寸 (200, 200, 3)
torch.Size([1, 3, 300, 300])
上采样后图片大小 (300, 300, 3)
1
2
3
2
3
图片下采样后的效果

在计算机视觉中,interpolate函数常用于图像的放大(即上采样操作)。比如在细粒度识别领域中,注意力图有时候会对特征图进行裁剪操作,将有用的部分裁剪出来,裁剪后的图像往往尺寸小于原始特征图,这时候如果强制转换成原始图像大小,往往是无效的,会丢掉部分有用的信息。所以这时候就需要用到interpolate函数对其进行上采样操作,在保证图像信息不丢失的情况下,放大图像,从而放大图像的细节,有利于进一步的特征提取工作。
# 3. 反池化unpooling
最大池化的相反过程,对应于最大值的地方填写最大值,其他位置补0

反最大池化需要记录池化时最大值的位置,反平均池化不需要此过程。
# 3.1 nn.MaxUnpool2d
MaxUnpool2d — PyTorch 1.11.0 文档 (opens new window)
#测试上采样
import torch
import torch.nn as nn
m = nn.MaxPool2d((3, 3), stride=(1, 1), return_indices=True)
upm = nn.MaxUnpool2d((3, 3), stride=(1, 1))
data4 = torch.randn(1, 1, 3, 3)
output5, indices = m(data4)
output6 = upm(output5, indices)
print('\ndata4:', data4,
'\nmaxPool2d', output5,
'\nindices:', indices,
'\noutput6:', output6)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
2
3
4
5
6
7
8
9
10
11
12
13
14
结果如下
data4: tensor([[[[ 1.9892, 0.1427, 2.5392],
[ 1.3678, -0.0524, 0.3090],
[ 0.7328, -1.1419, -0.8446]]]])
maxPool2d tensor([[[[2.5392]]]])
indices: tensor([[[[2]]]])
output6: tensor([[[[0.0000, 0.0000, 2.5392],
[0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000]]]])
1
2
3
4
5
6
7
8
2
3
4
5
6
7
8
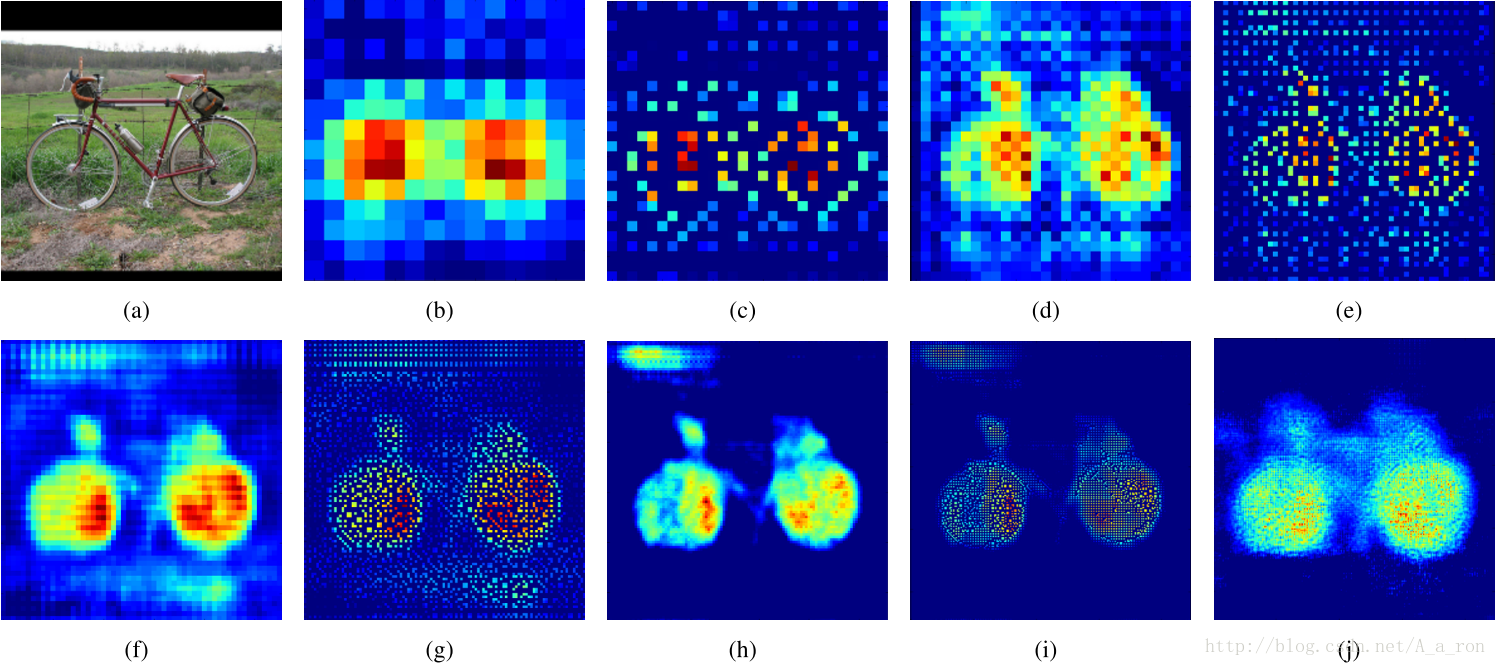
图(a)是输入层;
图(b)是反卷积的结果;
图(c)是的UnPooling结果;
图(d)是的反卷积结果;
图(e)是的Unpooling结果;
图(f)是反卷积的结果;
图(g)是 UnPooling的结果;
图(h)是的反卷积的结果;
图(i)和图(j)分别是的UnPooling和反卷积的结果。两者各有特点。
# 4. 上采样unsampling
在空隙中填充同样的值
# 4.1 nn.Unsampling
torch.nn.Upsample(size=None, scale_factor=None, mode='nearest', align_corners=None)
1
size:据不同的输入制定输出大小;scale_factor:指定输出为输入的多少倍数;mode:可使用的上采样算法,有nearest,linear,bilinear,bicubic和trilinear。默认使用nearest;align_corners:如果为 True,输入的角像素将与输出张量对齐,因此将保存下来这些像素的值。
# nearest最近邻
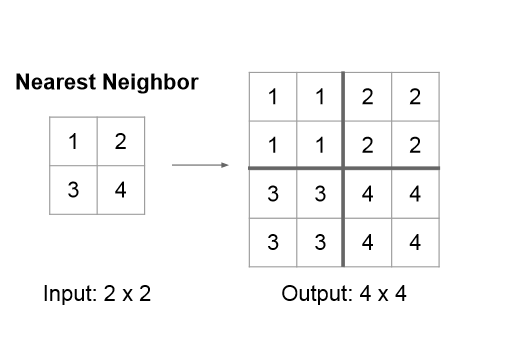
代码样例
import torch
import torch.nn as nn
input_image = torch.tensor([[[[1., 2.],
[3., 4.]]]])
model = nn.Upsample(scale_factor=2, mode='nearest')
out=model(input_image)
print(out)
1
2
3
4
5
6
7
8
2
3
4
5
6
7
8
结果如下
tensor([[[[1., 1., 2., 2.],
[1., 1., 2., 2.],
[3., 3., 4., 4.],
[3., 3., 4., 4.]]]])
1
2
3
4
2
3
4
# bilinear双线性差值
import torch
import torch.nn as nn
input_image = torch.tensor([[[[1., 2.],
[3., 4.]]]])
m = nn.Upsample(scale_factor=2, mode='bilinear', align_corners=False)
o = m(input_image)
print(o)
1
2
3
4
5
6
7
8
2
3
4
5
6
7
8
结果
tensor([[[[1.0000, 1.2500, 1.7500, 2.0000],
[1.5000, 1.7500, 2.2500, 2.5000],
[2.5000, 2.7500, 3.2500, 3.5000],
[3.0000, 3.2500, 3.7500, 4.0000]]]])
1
2
3
4
2
3
4
# 4.2 nn.UpsamplingNearest2d
如果你使用的数据都是JPG等图像数据,那么你就能够直接使用下面的用于2D数据的方法:
专门用于2D数据的线性插值算法,参数等跟上面的差不多,省略
import torch
import torch.nn as nn
input_image = torch.tensor([[[[1., 2.],
[3., 4.]]]])
m = nn.UpsamplingNearest2d(scale_factor=2)
o =m(input_image)
print(o)
1
2
3
4
5
6
7
8
9
2
3
4
5
6
7
8
9
结果如下
tensor([[[[1., 1., 2., 2.],
[1., 1., 2., 2.],
[3., 3., 4., 4.],
[3., 3., 4., 4.]]]])
1
2
3
4
2
3
4
效果和下面的这段代码是一样的
import torch
import torch.nn as nn
input_image = torch.tensor([[[[1., 2.],
[3., 4.]]]])
model = nn.Upsample(scale_factor=2, mode='nearest')
out = model(input_image)
print(out)
1
2
3
4
5
6
7
8
2
3
4
5
6
7
8
还要
import torch
import torch.nn as nn
input_image = torch.tensor([[[[1., 2.],
[3., 4.]]]])
m = nn.UpsamplingBilinear2d(scale_factor=2)
o=m(input_image)
print(o)
1
2
3
4
5
6
7
8
2
3
4
5
6
7
8
CNN中几种upsample方法 - 简书 (jianshu.com) (opens new window)
CV03-双线性差值pytorch实现_苦行僧(csdn)的博客-CSDN博客_pytorch 双线性插值 (opens new window)